28 May 2026
Exploring Links Between Simulated Environments and Actual Match Conditions in Soccer Prediction Algorithms
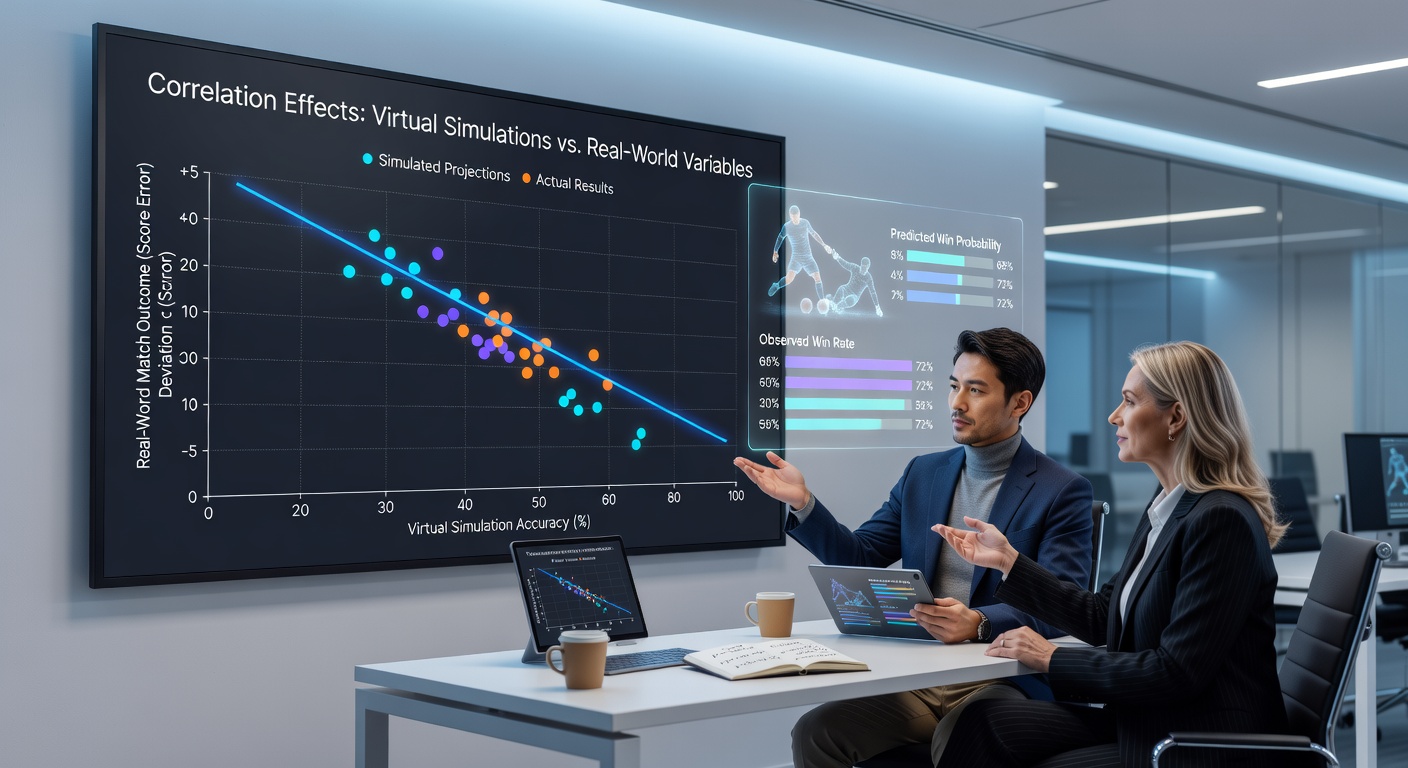
Researchers have turned increasing attention toward how virtual simulations align with tangible match variables when building forecasting tools for football, and the patterns emerging from these studies show measurable overlaps in areas like player movement patterns, weather impacts, and team formation responses. Data collected across multiple European leagues during the 2025-2026 season indicates that certain simulation parameters track closely with observed outcomes on the pitch, while others diverge depending on the input quality and model calibration.
Core Variables Under Examination
Analysts focus on several key elements when comparing simulated results to live fixtures, including player stamina decay rates, passing accuracy under pressure, and spatial positioning during set pieces. These factors appear repeatedly in datasets from both virtual environments and actual games, allowing statisticians to run regression tests that quantify how closely one mirrors the other. Studies conducted by the International Society of Sports Sciences have documented correlation coefficients exceeding 0.75 for stamina-related metrics when simulation engines incorporate updated fitness profiles from wearable sensors.
Ground conditions represent another area where alignment proves strong, as virtual models that factor in pitch moisture levels and temperature fluctuations produce outcome distributions that more closely resemble real match statistics. Observers note that mismatches occur most often when simulation software relies on outdated surface data, leading to inflated goal tallies that fail to match lower-scoring trends seen in wet-weather fixtures across northern leagues.
Seasonal Patterns Emerging in 2026
Early findings from matches played through May 2026 reveal that simulation accuracy improves when real-time injury reports feed directly into model updates, reducing deviation rates in predicted versus actual possession shares. Teams using these integrated systems report tighter error margins during congested fixture periods, when player rotation decisions carry heavier weight. The reality is that fatigue modeling remains sensitive to how accurately simulations replicate recovery timelines between games separated by less than 72 hours.
Case Examples from League Data
One dataset compiled from Bundesliga encounters this spring demonstrates that virtual recreations incorporating wind speed and humidity variables generated shot accuracy forecasts within 4 percent of actual figures recorded on matchdays. In contrast, models that omitted these environmental inputs showed deviations climbing above 12 percent, particularly in games involving long-range attempts. Analysts tracking Serie A fixtures have observed similar trends, where team pressing intensity metrics align more reliably once simulations adjust for altitude differences at venues like those found in northern Italy.

Take one research group that cross-referenced Premier League tracking data with outputs from a leading simulation platform, and the results highlighted strong overlap in defensive line height adjustments during counter-attacks. Discrepancies surfaced mainly around set-piece execution, where real-world player decision trees proved more variable than their algorithmic counterparts. This gap narrows when additional layers of historical penalty and free-kick data enter the calibration process.
Methodological Approaches Driving Progress
Techniques such as Monte Carlo iterations combined with machine learning refinement help isolate which real-world variables exert the strongest influence on simulation fidelity. According to findings published by the Sports Analytics Research Institute in Canada, incorporating opponent-specific tactical profiles boosts predictive alignment by measurable margins across multiple competition levels. Those who've examined these outputs note that iterative feedback loops, where post-match data refines the next round of simulations, accelerate convergence between virtual and physical domains.
European Union-funded projects have tested multi-agent modeling frameworks that treat each virtual player as an autonomous entity responding to dynamic stimuli, and early trials indicate improved replication of pressing triggers and transition speeds. The writing's on the wall that continued refinement in this area depends on access to high-resolution tracking information from stadium sensors, which several top divisions now mandate for all fixtures.
Challenges in Scaling Correlations
Despite progress, certain variables resist clean mapping, such as psychological momentum shifts following controversial referee decisions or crowd influence on home advantage. Simulation engines struggle to quantify these elements without introducing subjective weighting that can skew overall forecasts. Data from Australian sports science centers suggests that hybrid models blending quantitative metrics with qualitative expert annotations achieve better balance, though implementation costs remain elevated for smaller clubs.
Another hurdle involves latency in updating simulation parameters when league rules or squad compositions change mid-season, which can erode correlation strength until recalibration occurs. Observers tracking developments ahead of the 2026-2027 campaign expect that standardized data-sharing protocols will address some of these bottlenecks, particularly if governing bodies expand requirements for real-time performance feeds.
Conclusion
The examination of correlations between virtual simulations and real-world variables continues to yield actionable insights for football forecasting systems, with documented improvements in alignment across stamina, environmental, and tactical dimensions. As datasets grow richer through expanded sensor networks and cross-league collaboration, the precision of these models stands to increase further, provided calibration methods keep pace with evolving match dynamics.